





|
|
|
|
|
|
|
CISC vs. RISC: Suitablity for pipeliningBy Simon LoaderRISC architectures lend themselves more towards pipelining than CISC architectures for many reasons. As RISC architectures have a smaller set of instructions than CISC architectures in a pipeline architecture the time required to fetch and decode for CISC architectures is unpredictable. CISC architectures by their very name also have more complex instructions with complex addressing modes. This makes the whole cycle of processing an instruction more complex. Pipelining requires that the whole fetch to execute cycle can be split into stages where each stage does not interfere with the next and each instruction can be doing something at each stage. RISC architectures because of their simplicity and small set of instructions are simple to split into stages. CISC with more complex instructions are harder to split into stages. Stages that are important for one instruction may be not be required for another instruction with CISC. The rich set of addressing modes that are available in CISC architectures can cause data hazards when pipelining is introduced. Data hazards which are unlikely to occur in RISC architectures due to the smaller subset of instructions and the use of load store instruction to access memory become a problem in CISC architectures. CISC instructions that write results back to memory need to be handled carefully. Forwarding solutions used for allowing result written to registers to be available for input in the next instruction become more complex when memory locations which can be addressed in various modes can be accessed. Write after Read hazard must be taken care of where CISC instruction may auto increment a register early in the stages which may be used by the previous instruction at a later stage. CISC added complexity makes for larger pipeline lengths to take into account more decoding and checking. Using the Larson and Davidson equation from their paper Cost-effective Design of Special-Purpose Processors: A Fast Fourier Transform Case Study for calculating the optimum number of pipeline stages for a processor it can be shown RISC architectures suite smaller pipelines. Keeping the values for instruction stream length and logic gates for stages static it can be shown that the optimum pipeline length increases with the size of the fetch execute cycle. 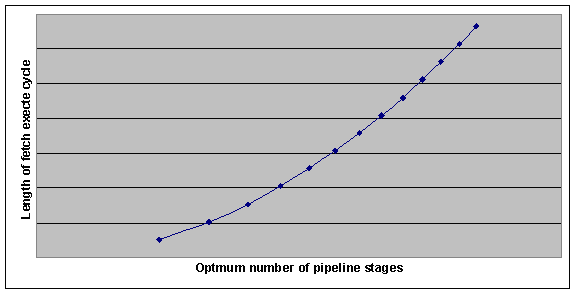 This is because with a large number of logic gates for a fetch execute cycle the additional gates required for stages have less impact. As RISC architectures have simpler instruction sets than CISC the number of gates involved in the fetch execute cycle compare will be far lower than this in CISC architecture. Therefore RISC architectures will tend to have smaller optimum pipeline lengths than more general processors. RISC architectures do suite pipelining more than CISC architectures and do lend themselves to smaller pipelines. This does not mean however that CISC architecture can not gain from pipelining or that a large number of pipeline stages are bad (although the flushing of a pipeline would become of concern). About the author: Simon Loader is a UNIX and email specialist who runs Surf, a free IT resource and downloads website, in his spare time . Many of the downloads and articles on Surf created by Simon are featured in technical websites all over the world. To access FREE downloads and information covering several diverse IT topics visit www.surf.org.uk. |
|||||||||||||||